HS编码智能匹配系统
一、智能体简介
在国际贸易中,准确的海关商品编码(HS编码)是货物通关与确定关税的基础。然而,HS数据库庞大(接近8000行)且不断更新,人工查找耗时耗力且易出错,同时传统的检索模型在面对中英混杂输入时往往会出现严重的性能下降与注意力偏差。
本智能体采用创新的“翻译 - 编码 - 匹配”三阶流水线一体化架构,通过大模型进行商务英语标准化预处理,结合轻量级文本编码器与双重语义匹配算法,打造了一款即开即用的智能化海关编码检索助手,大幅降低了企业的合规风险与人力成本。
二、 核心功能
商务英语级智能预处理:系统内置Qwen3-30B-Instruct模型,通过结构化提示词将用户输入的中英混杂文本统一转化为严谨的商务英语,有效消除了多语种翻译中常见的术语歧义(如将“live”准确区分)。
全局与局部双效语义匹配:在计算整体句级余弦相似度的基础上,将输入文本拆分为特征子串进行局部语义相似度检索,作为额外加分项。该机制有效避免了模型优先关注“材质”而非“类别”的注意力偏移问题。
内存级向量库热更新:系统在首次启动时将海量HS注释一次性编码为10MB大小的本地pt文件并常驻内存,查询全程无磁盘IO。当海关税则调整时,支持10秒内热加载增量编码,新税号即刻生效。
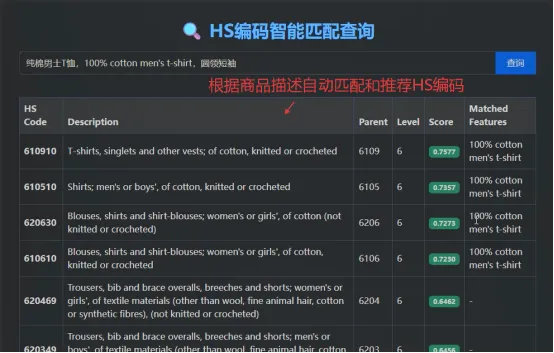
Web端可视化交互:提供直观的Web查询界面,不仅返回最佳匹配的HS Code和描述,还会详细展示层级、综合评分(Score)以及触发加分的局部匹配特征(Matched Features)。
三、应用成效
极致低成本运行:不依赖任何昂贵的显卡或计算卡加速,在轻量级的纯CPU服务器环境中即可实现高速推理与流畅运行。
高精度的检索表现:通过预处理与优化的匹配算法,成功弥补了小巧文本编码器的性能不足,解决了多语种混杂场景下的检索难点。
四、创新亮点
统一语言预处理:放弃传统的多语言直接检索模式,利用大模型将输入统一翻译为英文,从根源上解决因口语化输入或多语种混杂导致的检索精度下降问题。
双重语义匹配:采用“全局+局部”相结合的语义检索方法,有效避免了模型仅关注单一局部特征(例如优先关注“材质”而非“类别”)所引发的注意力偏移与语义误差。
极简轻量化部署:跳出目前业内常见的“大模型+RAG”的算力内卷路径,大胆选用轻量级免费开源模型,极大降低了外贸企业的硬件门槛与部署成本。
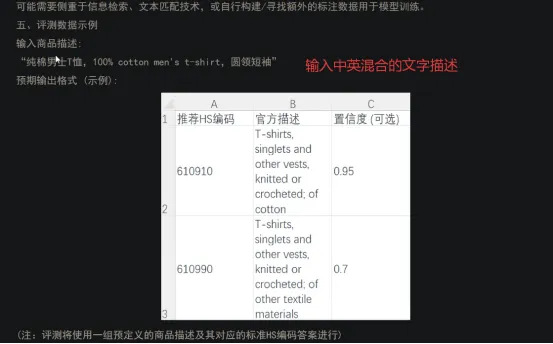
五、智能体展示